作者丨一般酱
修改丨好了你不要再说了
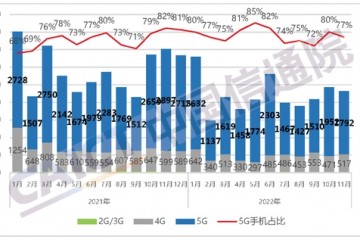
“洛阳纸贵”。自2016年起,纸类产品,包含全新的纸浆与纸产品,以及废纸的收回价格都走出了过山车相同的折线图。
在“纸”这个传统常识载体上,折射出的满是新经济作用于社会所发作的一系列结果:电商等事务催生的包装需求、现代经济社会对环境提出的更高要求,清退落后产能与约束抛弃纸张进口,都在无形中推升纸价。
废纸是可再生资源,而现代的常识与信息载体——例如硬盘——就没有这么好的待遇了。
pixabay
一方面,数据很软弱,就在本文发布的12月26日下午,微信大众号后台溃散,大众号们曾发布的信息,暂时与读者断开衔接。
另一方面,数据还有点贵。数据的存储与运用都有看得见本钱,有务实的公司打起了清空前史数据的主见。
本年10月,老牌互联网公司yahoo曾有一则新闻,标题现已很好地总结了新闻内容,大概是这个画风[1]:
《yahoo宣告逐步关闭“yahoo群组”网站,12月14日后删去一切上传内容》
新闻一出就惹了公愤。yahoo群组是yahoo公司在2001年推出的一个线上谈论社区,也是世界上最大的网络社区之一。(其运营者yahoo公司于2017年被美国电信职业巨子Verizon收买。)
依据NPR(美国公共广播电台)的报导[2],一些互联网前史研讨者对删去数据的行为表明剧烈对立,他们都以为,yahoo群组保存了包含关于9·11作业在内的许多前史谈论,是研讨互联网前期前史的绝佳窗口。
在NPR的谈论者中,有一位致力于保存yahoo群组数据的非盈利安排的作业人员。无独有偶,在闻名论坛Reddit上,也有用户开端为了保存yahoo群组数据开发各类东西[3]。但yahoo并不答应这样的作业发作——yahoo宣告封禁了上百个企图存档yahoo群组数据的账号,想保存数据?没门。
Verizon封禁了企图备份yahoo群组的账号 | 图:ZDNet
这个作业的最新消息是,yahoo为个人数据延长了一个多月的“保质期”,让个人用户都能够导出数据。想从更高维度审视这些自发构成、群力建立的网络遗址?不好意思,此路依然不通。
数据遗址,谁来维护?
在人类的前史上,通常是大巨细小的图书馆、博物馆承当“保存信息”这个重大任务,它们完成了常识的传承与文明的记载。而在曩昔的信息年代几十年里,人类发明了史无前例的信息财富,这些记载的载体,正是保存着数据的硬盘(当然,还有其它数据载体)。
但,人类真的在好好记载这个年代吗?
BBC在本年4月宣告的一篇谈论曾提出这样的一个问题[4]:前期互联网前史存档内容为何如此之少?
他们找到了更多数据丢掉的事例:同属电信巨子Verizon旗下的互联网门户“美国在线”(AOL),曾在2013年关闭旗下一切音乐网站,数百位撰稿人及数十位修改的多年作业效果简直悉数消失。终究,作者失望地以为,即运用户将相片发送到Facebook这样如日中天的渠道上,也迟早有一天会像已被关闭的Google+相同失掉一切内容。
前期互联网前史存档为何如此之少?| 图:BBC
史学研讨者推重王国维提出的“二重证据法”,寻求“纸上之资料”与“地下之资料”的彼此参证。在互联网年代,数据便是这“纸上之资料”。尊重数据的公司也是有的,它们正在致力于建造数据的图书馆。
建立于1996年的互联网档案馆(Internet Archives)致力于存档各个网站的网页,但即便现已建立三十多年,互联网档案馆依然缺席了互联网刚刚诞生的那五年,而且也不或许存档下整个互联网——更何况跟着移动互联网诞生,现在的信息更多散落在关闭系统内,而不是能够揭露拜访、记载的网站页面了。
数据无法获取,存储也是难题。有一些公司正在企图把更多的数据更持久地保存下去。
在上个月,代码保管渠道Github宣告[5],方案将包含Linux、Android在内的6000多个盛行开源项目的源代码,以胶片方式存储并封存在北极地下250米的仓库里,估计这些数据能够保存上千年。另一方面,针对长时间、低本钱保存数据的需求,也有公司在活跃开发相应的技能。例如微软最近宣告了一项在石英玻璃上用激光刻蚀存储数据的技能[6],宣称能够在一片杯垫巨细的玻璃上刻入一部电影母带的容量,能够保存数千年。
百年之后,前史数据归于谁?
保存数据,除了需要用情怀去掩盖本钱以外,还有一个务虚的问题:用户发作的数据,在更久远的前史视角上,数据的一切权将归于谁?
关于依然健在的公司来说,杂乱的用户协议中往往对用户发作的数据做出了许多免责规则,乃至将用户内容的一切权(著作权等)归于渠道,而且不对数据的保存期限做出确保。而关于现已消失的公司,从前的用户协议也现已和前史数据相同成了“故纸堆”。
在2015年的《纽约时报》的一则报导[7]查询了 99 个有英文服务条款或许隐私方针的网站,其中有 85 个网站称,它们或许会在吞并、吞并、破产、财物出售或许其他买卖发作时搬运用户的信息。
咱们或许现已对数据的发作与消失变得麻痹——各类网盘、博客渠道的关停层出不穷。而除了关停,还有更多的数据被雪藏,如百度贴吧,这个与yahoo群组相似的产品,相同记载着许多关于某些时间的言论史料,这些记载至今已无法追溯。
别的一个问题是,即便这些信息都能够追溯并保存上千年,但这些由用户奉献、明显带有个人特征及隐私的内容,能否进入公共范畴,成为每个研讨者都能够引述的目标?
在没有互联网的年代,传统的出书业部分解决了这样的一个问题。咱们至今还能看到很多的名人日记出书,有些名人,像清末的李慈铭和民国年代的胡适,乃至在生前就开端出书日记。这些内容也得益于揭露出书而免于散佚。
但“名人日记”总之不同于平民百姓的朋友圈日常吐槽,在日益着重“隐私”和“权益”的今日,你在网上的讲话,在几年、几十年乃至上百年后,被一记“洛阳铲”挖出来作为史料研讨,还需要你来赞同、赞同与署名吗?
新一轮“文献灾祸”的罪魁
中外前史上曾发作过很多次“文献灾祸”。
亚历山大图书馆,这座或许是世界上最早的图书馆,其收藏的很多古代典籍,数次毁于兵火;十字军东征期间,开罗、叙利亚图书馆的旧藏也遭统治者变卖充军饷;而在我国,古人将文献灭失作业称为“书厄”,意为“书本遭受的劫难”。从隋代的“五厄”到明代的“十厄”,再到近现代的“十五厄”,文献消除作业从未中止。
总结起来,人类前史上文献消失可分为如下几类要素:
一来是政治劫难,历代禁书活动也因表里交困不得不卖书求生的作业,从未中止;
二来是战役要素,每逢表里战役或改朝换代,由于战役导致的图书被焚毁和抢掠作业不断。如鸦片战役期间,我国最早的私家藏书楼天一阁遭抢;清圆明园藏书楼文源阁,因英法联军侵略而遭毁;
三来是天然要素,一些条件杰出的藏书楼,由于天火、水灾等天然要素而遭毁,如粤雅堂藏书在“十三行大火”中被毁;俄罗斯科学院社会科学信息研讨所起火,导致所内图书馆被烧。
但互联网却显得更特别:市场经济条件下,假使无人愿花钱保存这些文献,咱们也无法横加指责;有人以隐私之名回绝揭露资源,前史研讨者们也只能无可奈何。
年代在前进,互联网向咱们展现了技能是怎么容易打破信息不对称,但终究,技能也暴露出其难以克服的缺点:它不能为咱们保存更多前史,乃至给消除前史带来更多便当。
下一轮“文献灾祸”,或许离咱们并不远。